
 Windows App
Windows App  MacOS (sillicon)
MacOS (sillicon) 

You spent three days evaluating AI frameworks. You read the documentation, watched the demos, and picked one. Then it shipped to production. Somewhere between the workflow configuration and the first live task, the agent hallucinated a data source, stalled mid-execution, and gave you no trace of what went wrong.
That is not a configuration problem. That is what happens when a framework built for demos meets work that actually matters.
The market for agentic AI frameworks has exploded in 2025 and 2026. LangChain, CrewAI, AutoGen, every engineering blog has a comparison. Most stop at API shape and quickstart speed. None of them tells you what happens when an agent fires a tool call on real data, in a real system, under real pressure. This article does.
What Agentic AI Frameworks Actually Are, And Where They Break
An agentic AI framework is not a chatbot wrapper. It is the infrastructure that lets a model plan, act, observe results, and adjust, step by step, without a human holding its hand through each decision. The framework manages the reasoning loop, tool connections, state across steps, and agent coordination.
The three dominant open-source agentic AI frameworks each solve this differently. LangGraph, the current evolution of LangChain, models workflows as stateful graphs. CrewAI uses a role-based crew metaphor to coordinate specialist agents. AutoGen treats agent interaction as a structured conversation, though Microsoft shifted new feature development to its Agent Framework successor in late 2025.
Each one is competent at what it was designed for. None of them resolves what most teams actually hit in production: the gap between building an agent and trusting one.
LangChain / LangGraph: Maximum Control, Maximum Overhead
LangGraph reached v1.0 in late 2024 and became the default runtime for LangChain agents. It models workflows as directed graphs where nodes are functions and edges define execution paths. State is explicit, typed, and persistent across steps, giving you fine-grained control over branching logic, error recovery, and human-in-the-loop checkpoints.
The tradeoff is real. A straightforward agent that calls a tool and returns a result requires more boilerplate than it should. Documentation churns frequently; tutorials from three months ago often break with the current version. That is not a minor inconvenience for teams under delivery pressure.
LangGraph is the right call when you need durable, auditable workflows and have engineers who understand graph primitives. It is the wrong call when you need to move fast.
CrewAI: Fast to Start, Honest About Its Ceiling
CrewAI’s insight is simple. Most multi-agent tasks look like a team of specialists. So it models them that way, each agent gets a role, a goal, a set of tools, and a backstory that shapes its behavior. Coordination happens automatically. You describe the crew; the framework figures out the handoffs.
That abstraction works well at prototype speed. A marketing team can have a research agent, a drafting agent, and an editing agent running in parallel within hours. For small-to-mid-scale automation where the workflow is well-defined and the stakes are moderate, CrewAI earns its reputation.
The ceiling reveals itself when workflows get irregular. Multi-agent conversations consume tokens at a rate that adds up fast. A higher level of abstraction means less direct state control. And when something breaks, finding where it broke is harder than it should be for production systems.
AutoGen: Research-Grade, Transitioning in Public
AutoGen pioneered conversational multi-agent architecture. Agents exchange messages, delegate tasks, and reach consensus through structured dialogue rather than predefined workflows. That flexibility made it the preferred framework for research teams running complex, dynamic tasks.
Microsoft moved new feature development to its successor to the Agent Framework in late 2025. AutoGen still receives security patches, but new systems built on it are inheriting a maintenance-mode codebase. For teams already inside the Microsoft stack, Azure, Semantic Kernel, enterprise identity, the Agent Framework is where the investment is going. For everyone else, it is a risk worth pricing carefully before committing.
Where All Three Frameworks Leave the Same Gap
Here is what none of the major agentic AI frameworks solve for you. The agent plans a research task. It calls a live source. The source returns current data. The model summarizes it, with full confidence, and gets the numbers wrong.
The framework ran correctly. The reasoning loop is completed. The output is wrong, and there is no trace of where the reasoning failed.
This is not a rare edge case. It occurs when autonomous execution runs on a model that still relies on training data. The framework handles orchestration. It does not handle accuracy. Those are two separate problems, and most comparison articles treat them as one.
Barie: Agentic AI Built Around the Accuracy Problem First
Barie was built because organizations using AI tools for serious research kept getting confidently wrong outputs. The product exists because that problem is real, it costs real work, and none of the existing frameworks were designed to solve it at the architecture level.
Barie’s Skills system is where execution lives. A Skill is a modular workflow that includes deep competitive research, financial statement analysis, SEO audit, and legal document review, all run with live web sourcing, parallel subtask execution, and source visualization in every output. Every claim in the result is traceable. You get a structured report that lets you trace any finding back to its origin.
The Connectors layer is what makes Barie an execution agent, not just a research tool. Connect Barie to your apps, Shopify, Notion, your project board, and a single prompt can pull data from one system and push output to another.
Barie’s Deep Research mode runs parallel subtasks simultaneously. When a founder asks for a competitive analysis of five tools, Barie does not research each tool individually. It fires all five in parallel, synthesizes the outputs, and delivers a structured brief with live citations. What takes an analyst a full day takes Barie one session.
The benchmark exists. Barie aces the GAIA Level 3 benchmark, the standard test for complex, multi-step agentic task completion. It has processed over 1 million hallucination-free chats across 25+ industries. The published figure is 90% accuracy. That is not marketing copy; it is a number Barie publishes and stands behind.
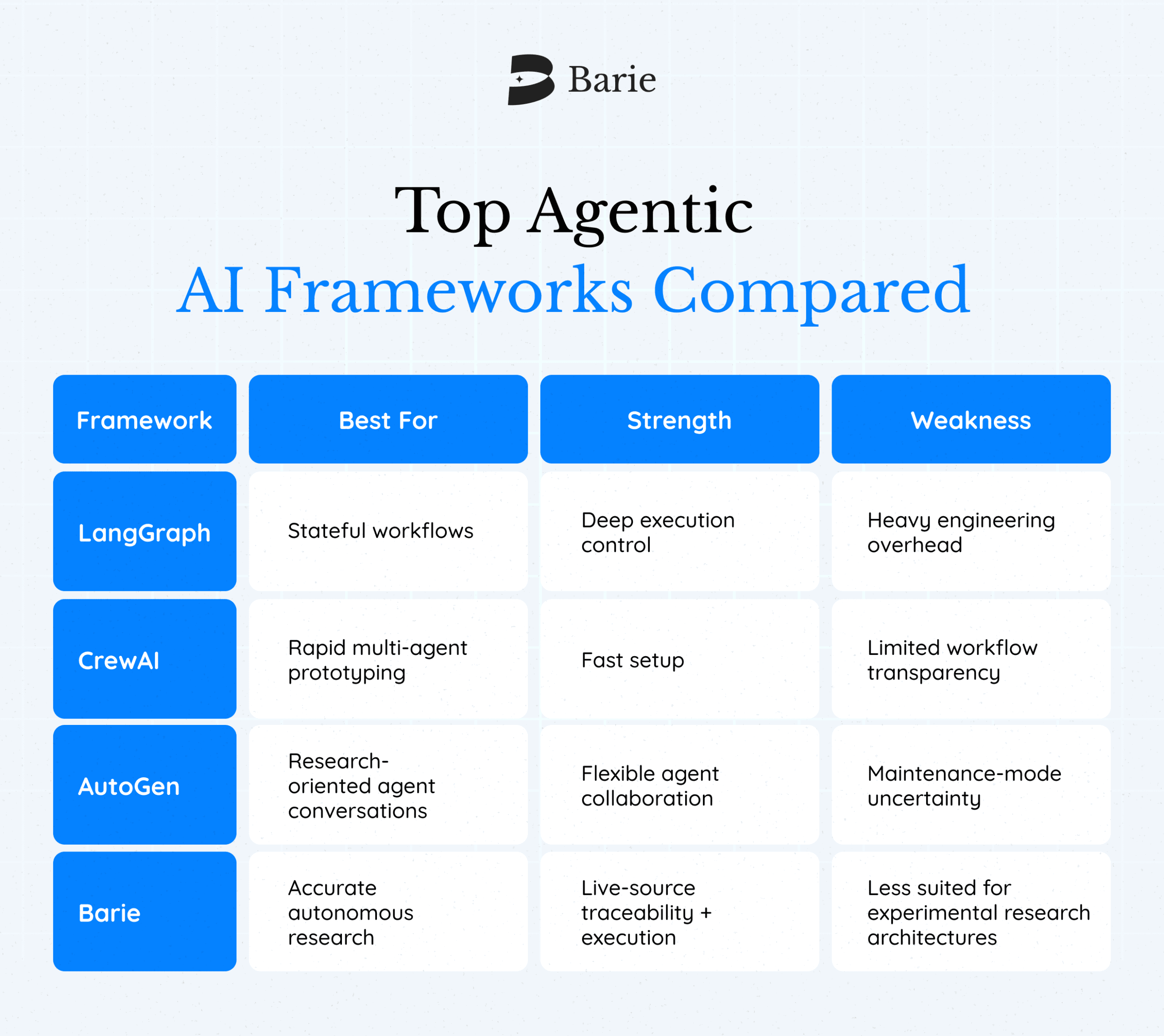
Choosing the Right Agentic AI Framework
The choice between LangGraph, CrewAI, and AutoGen comes down to three questions: How much control do you need over state? How fast do you need to ship? And what is the cost of a wrong answer in your workflow?
For stateful, long-running workflows where engineers know graph primitives, LangGraph gives the most control. For role-based team automation where prototype speed matters, CrewAI has the lowest barrier. For Microsoft-aligned environments, the Agent Framework is where the investment is going.
If your problem requires autonomous research on live data, delivered accurately, traceable to source, executable across connected apps, those three frameworks are solving a different problem than you have.
The Answer to a Question Most Frameworks Ignore
Most agentic AI framework comparisons end with a decision matrix. This one ends with a different question: what does accuracy cost you when your agent gets it wrong?
For a developer prototyping an automation, perhaps not much. For a founder making strategic decisions on fabricated competitive data, the cost is real. For a research team submitting findings that came from a hallucinated source, the cost is credibility.
Barie was built for the second and third scenarios.
Try Barie free, and get 900 credits. Start your first deep research session at



