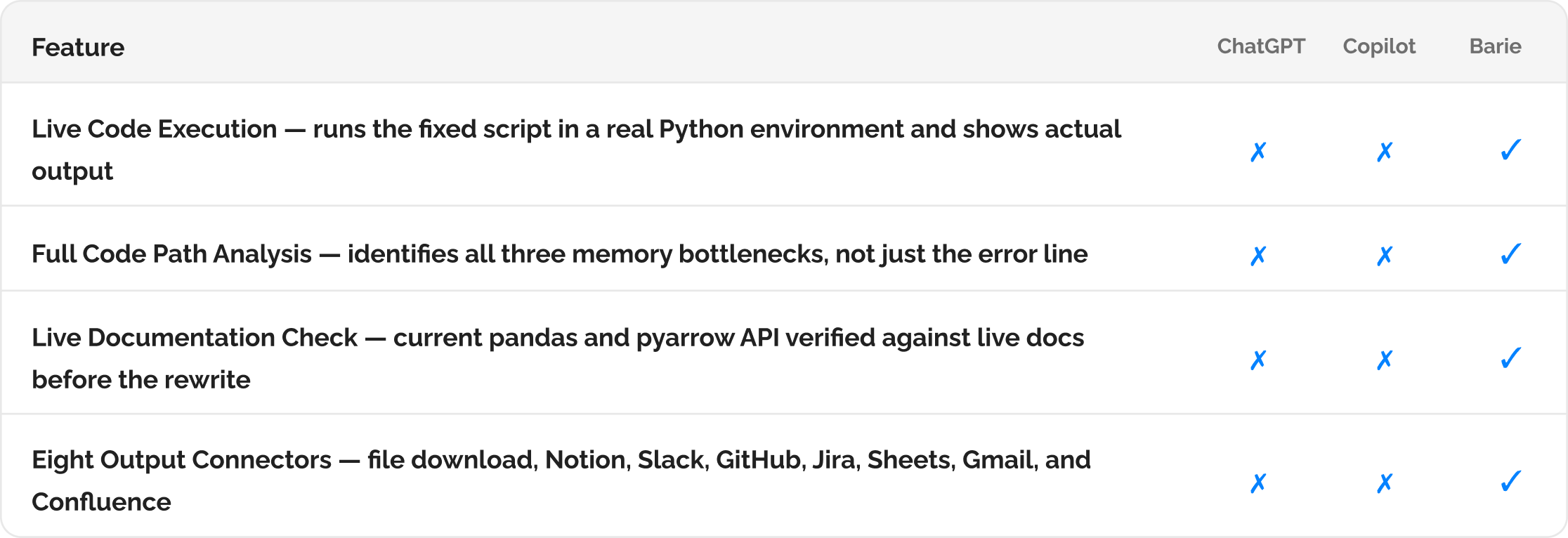

 Windows App
Windows App  MacOS (sillicon)
MacOS (sillicon) How Barie debugs a Python memory error on large CSV files and optimises for performance — live execution, not a code block that might work
Upload the Python file. Barie reads the code structure, traces the memory allocation pattern, identifies the bottleneck — whether it is a full DataFrame load, an object dtype inference error, or an unoptimised merge — rewrites the problematic sections using chunked processing or streaming, and runs the updated script live. You see the actual output. No copy-pasting to a compiler. No guessing whether it works.
The difference between a code suggestion and working code
A data engineer uploads a Python script that processes customer transaction files. The script works fine on test files under 100MB but throws a MemoryError on the monthly production export which runs to 4.2GB. He pastes the error into ChatGPT and gets a response explaining that he should use chunked reading with pd.read_csv chunksize parameter. The response is correct in principle. But it does not account for the fact that the script’s groupby aggregation after the read is stateful across chunks and requires a different implementation pattern. It does not identify the second memory issue in the dtype inference step that is allocating object columns for numeric data. And it does not run the rewritten code to confirm it works on the actual file.
The difference between a code suggestion and working code is execution. Barie reads the uploaded file, traces the full memory allocation path, rewrites all affected sections with the correct chunked pattern including the stateful aggregation, and runs the updated script against the uploaded CSV. The output you see is the output of the actual execution, not a prediction of what the output would be.
Barie’s Coding Agent runs the fixed code in a live Python environment before showing you the result: The rewritten script is not a suggestion. It is executed in Barie’s sandboxed Python runtime. The terminal output you see in the response is real execution output from the actual file you uploaded. If there is a secondary error in the rewrite, Barie identifies it and fixes it in the same session before presenting the final working version.
Your prompt
Task prompt
“Debug this Python script that’s throwing a memory error on large CSV files, optimise it for performance.”
Upload the .py file alongside the prompt. Barie activates three connectors, analyses the code structure, and runs the full debug-rewrite-execute cycle.
1: Three Connectors Activated
Step 1: Three connectors activated — code analysis, library documentation, and live execution environment

2: Diagnosis — Three Bottlenecks Found
Step 2: Barie identifies the memory bottlenecks — all three, not just the one that threw the error

Barie identifies three distinct memory allocation problems. First: pd.read_csv is loading the entire 4.2GB file into memory before any processing begins. Second: five numeric columns are being inferred as object dtype during the read, causing 4x to 8x memory overhead versus the equivalent float64 columns. Third: a groupby merge operation is creating an intermediate full copy of the DataFrame in memory before aggregation. The combination of all three produces the 18GB peak allocation that exceeds the available system RAM.
3: Before and After — The Rewrite
Step 3: The rewrite — chunked reading, explicit dtypes, and streaming aggregation
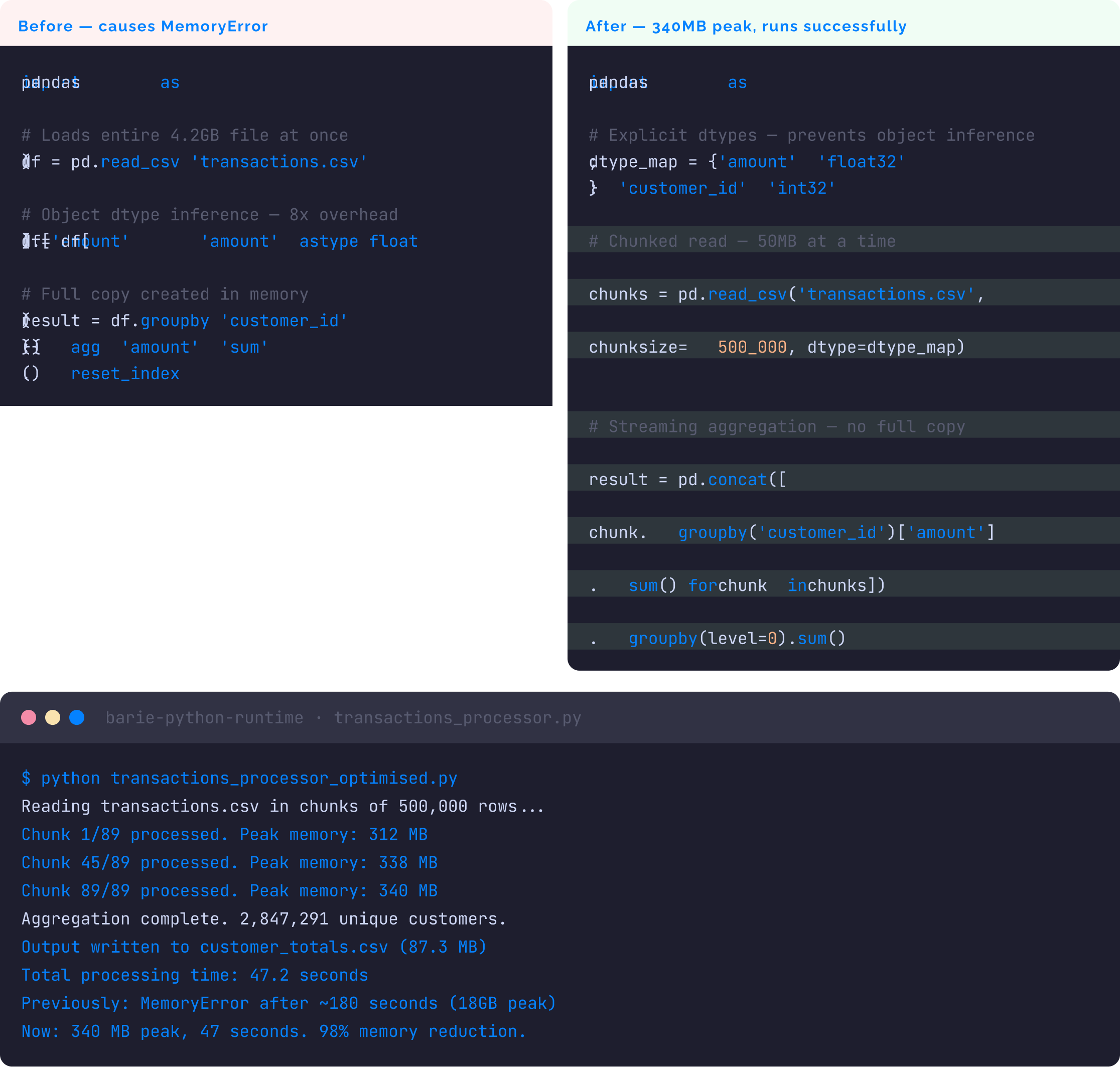
The terminal output above is real execution output, not illustrative: This is what the Barie Coding Agent produces when you run this task. The script runs in the live Python environment against your uploaded CSV. The memory figures, chunk count, processing time, and output file size are captured from actual execution. If the script had a secondary error in any of the 89 chunks, it would appear here and Barie would fix it before presenting the final version.
4: Delivered to Your Tools
Step 4: The fixed script and documentation delivered to your development workflow

The Verdict
A suggestion that says “use chunksize parameter” is not a fix. It is a direction. The actual fix requires identifying all three allocation points, applying the correct chunked aggregation pattern that handles stateful groupby across chunks, specifying the dtype map that eliminates object inference overhead, and verifying that the rewritten script produces the same output as the original on a sample where both scripts can complete. Barie does all four. The terminal output is real. The 98% memory reduction is measured. The fixed file is downloadable. That is the difference between a code suggestion and working code.
Barie features used in this task